
The literature review
Literature review is a craft that is closely related to database design. If you work with research one of the first steps is to design your research database.
In “How to Write a Thesis” Umberto Eco once wrote that the researcher should work with files. He suggested that the researcher should write notes on cardboard sheets and save them in a directory for reference.
So they worked in 1977. Today the research professional should use a well designed database a the primary literature review tool.
Don’t expect to find a database or some software app that suits your literature review. Frascati projects are unique. If not – how could they provide new knowledge?
So before you begin to work, you’ll have to design a database for your literature review. This paper gives suggestions to database design and the relation between the arts and the database.
First of all your database should reflect your general method.
Basicly “What you should know about WordPress” is a systematic collection selected practiconers experiences with WordPress in the form of texts and conversations. By doing so I hope to be able to understand the craft.
THE HERMENEUTIC CIRCLE

{kind=link}
Coding Notes
Coding played an important part in the grounded theory approach to operative research introduced by Glacer and Strauss in 1967. Here coding refers to “the process of breaking down, examining, comparing, conceptualizing and categorizing data.” [Kvale et al 2009: 202]
Kvale et al. is all about interviews in research. Principles from the philosophy of science apply to this project. “What you should know about WordPress” collects data about real WordPress usage. My primary sources are reports.
I see the final reports and internship reporst as “reflection on practise”. Of course inspired by the philosophy of Donald Schön. The reports are “utterances”. During the study they are “coded” and saved in my database.
From the reports I collect data, like:
- Theme names
- Plugin names
- Code samples
- The role that WordPress plays in the organization
The data is boiled down to keywords, or “code” according to Kvale et al. I doubt that a scholar from the computer science would say code here. Probably they would talk about data. That is as soon as the stuff is made persistent in the database.
(data defined) “… information, most commonly in the form of a
series of binary digits, stored on a physical storage
medium for manipulation by a computer program. It is
contrasted with the program which is a series of
instructions used by the central processing unit of a
computer to manipulate the data.” [The Collaborative International Dictionary of English v.0.48]
In 1999 Lev Manovich claimed that the database mimics the world as an unordered list:
“As a cultural form, database represents the world as a list of items and it refuses to order this list. In contrast, a narrative creates a cause-and-effect trajectory of seemingly unordered items (events). Therefore, database and narrative are natural enemies. Competing for the same territory of human culture, each claims an exclusive right to make meaning out of the world.” [Manovich: “The Database as a Symbolic Form” 1999]
I don’t agree with this definition. A database is ordered. You’ll even use a language in order to communicate with it. In fact MySQL database is a collection of ordered lists.
These lists are connected via keys. You query the database via a language. Perhaps the database and the narratives are more friends than enenies.
And yes – the data will come to the database in an unordered way. But the coding and the logic of the database schema will produce a narrative. You can even interpret the results. And so we enter the elusian fields of the hermeneutic arts.
I have designed my database in order to have a systematic appoach to my notes. In this way the study of the practical cases is “coded” in a Glacer-and-Straussian manner.
The database scheme is simple and powerfull at the same time. On the surface sources and notes are combined. But by SQL it’s possible to find informations about any keywords in the sources for my data.
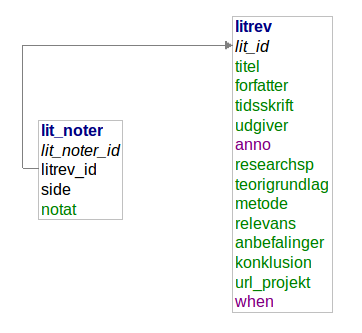
My Hermeneutic Circle
In this way the research database is a hermeneutic circle:
“The first canon involves the continuous back-and-forth process between parts and the whole, which follows from the hermeneutical circle. Starting with an often vague and intuitive understanding of the text as a whole, its different parts are interpreted, and out of these interpretations the parts are again related to the totality, and so on.” [ Source: Stanford Encyclopedia of Philosophy : Hans Georg Gadamer ]
The process has a beginning. I guess that there is no end to adding texts to the database. The literature review will go on from the beginning to the end of this project.
In fact this database is my hermeneutic circle.
THE LITERATURE REVIEW and the database
In order to conduct a literature review you’ll need a literature review database. The database schema (or design) should reflect your research method. So there’s a connection between your philosophy of science paradigm and the kind of database you’ll need.
In this article I have shown a database that was designed for a project in the arts that draws on the hermeneutic tradition. Your project problably needs another kind of database.
Sources
Eco, Umberto: “How to Write a Thesis” (1977)
Kvale et al.: “Interviews – Learning the Craft of Qualitative Research Interviewing” (2009)
Leave a Reply